Mit dem Start der Verwendung von OpenHAB entschied ich mich für die Verwendung von MySQL als Persistentzdienst, da ein MySQL-Server bereits vorhanden war. Nun wollte ich zu Influx-DB wechseln, da dort die Geschwindigkeit für größere Datenmengen in Verbindung mit Grafana deutlich größer ist.
Da ich aber meine alten Daten behalten wollte, stand ich vor einem kleinen Problem, da es keine Funktion gab um die alten Daten zu migrieren. Ich musste also eine eigene Lösung zur Migration von MySQL zu Influx-DB erstellen.
Meine Lösung möchte ich hier nun zur Verfügung stellen.
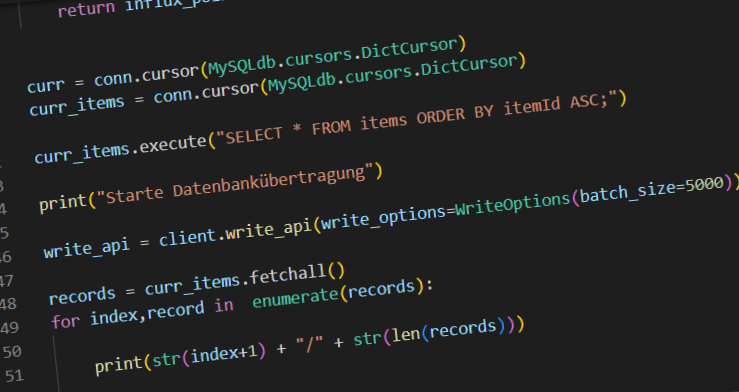
Zuerst habe ich Influx-DB als 2. Persistentsservice in OpenHAB eingestellt, damit neue Werte schon in die Influx-DB geschrieben werden. Dann habe ich ein Python-Script erstellt, welches alle Werte der OpenHAB-Items der SQL-Datenbank ausliest und in die Influx-DB kopiert.
Das Script sieht wie folgt aus:
### Einstellungen ###
### MYSQL ###
MYSQL_HOST = "192.168.0.2"
MYSQL_USER = "openhab"
MYSQL_PASSWORD = "123456"
MYSQL_DB = "openhab"
MYSQL_PORT = 3307
### INFLUX ###
INFLUX_DB_BUCKET = "openhab"
INFLUX_DB_HOST = "http://192.168.0.2:8086"
INFLUX_DB_TOKEN = "123456"
######################
import pymysql
pymysql.version_info = (1, 4, 13, "final", 0)
pymysql.install_as_MySQLdb()
import MySQLdb
conn = MySQLdb.connect(host=MYSQL_HOST, user=MYSQL_USER, passwd=MYSQL_PASSWORD, db=MYSQL_DB, port=MYSQL_PORT)
### InfluxDB info ####
from influxdb_client import InfluxDBClient, BucketRetentionRules, WriteOptions, Point
from influxdb_client.client.write_api import SYNCHRONOUS
client = InfluxDBClient(url=INFLUX_DB_HOST, token=INFLUX_DB_TOKEN, org="openhab", timeout=120_000)
SCHEMA_TIME_COLUMN = "time"
SCHEMA_FIELD_COLUMN = "value"
def generate_influx_points(records, measurement_name):
influx_points = []
for record in records:
influx_points.append(Point(measurement_name).tag("item", measurement_name).field("value", record[SCHEMA_FIELD_COLUMN]).time(record[SCHEMA_TIME_COLUMN]))
return influx_points
curr = conn.cursor(MySQLdb.cursors.DictCursor)
curr_items = conn.cursor(MySQLdb.cursors.DictCursor)
curr_items.execute("SELECT * FROM items ORDER BY itemId ASC;")
print("Starte Datenbankübertragung")
write_api = client.write_api(write_options=WriteOptions(batch_size=5000))
records = curr_items.fetchall()
for index,record in enumerate(records):
print(str(index+1) + "/" + str(len(records)))
if record is None:
break
item_name = record["itemname"]
curr.execute("SELECT DATA_TYPE FROM INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'item" + str(record["ItemId"]).zfill(4) + "' AND COLUMN_NAME = 'value' AND DATA_TYPE != 'timestamp'")
row_count = curr.rowcount
if row_count > 0:
curr.execute("SELECT * FROM " + "item" + str(record["ItemId"]).zfill(4) + " ORDER BY " + SCHEMA_TIME_COLUMN + " DESC;")
print("Item: " + item_name)
while True:
selected_rows = curr.fetchall()
print("Anzahl Werte: " + str(len(selected_rows)))
write_api.write(bucket=INFLUX_DB_BUCKET, record=generate_influx_points(selected_rows,item_name))
print("Geschrieben")
if len(selected_rows) < 10000:
break
conn.close()
print("Ende Datenbankübertragung")
Die Werte in den markierten Zeilen müssen nach den eigenen Bedürfnissen angepasst werden.
Wenn noch nicht vorhanden, müssen die benötigten Module installiert werden:
sudo pip3 install pymysql
sudo pip3 install influxdb-client
Wenn das Script durchgelaufen ist, sollten alle Werte aus der SQL-Datenbank in die Influx-Datenbank übertragen wurden sein und in OpenHAB über den Persistenzdienst der Influx-DB zur Verfügung stehen.